Large Language Models (LLMs) have revolutionized natural language processing, yet a persistent challenge remains: ensuring their outputs truly reflect user instructions. This misalignment can hinder efficiency and accuracy, especially in specialized tasks.
Current approaches address this issue by:
- Fine-tuning LLMs with human-annotated data: This method, exemplified by models like GPT-4, can be time-consuming and resource-intensive.
- Increasing instruction complexity: Frameworks like WizardLM+ enhance training data by incorporating more intricate instructions, as highlighted by Zhao et al. and Zhou et al.
- Automating synthetic data generation: Schick and Schütze propose leveraging LLMs’ capabilities to generate synthetic data, streamlining the training process.
- Knowledge distillation: Techniques pioneered by Hinton et al. refine LLMs for specific tasks by transferring knowledge from pre-trained models.
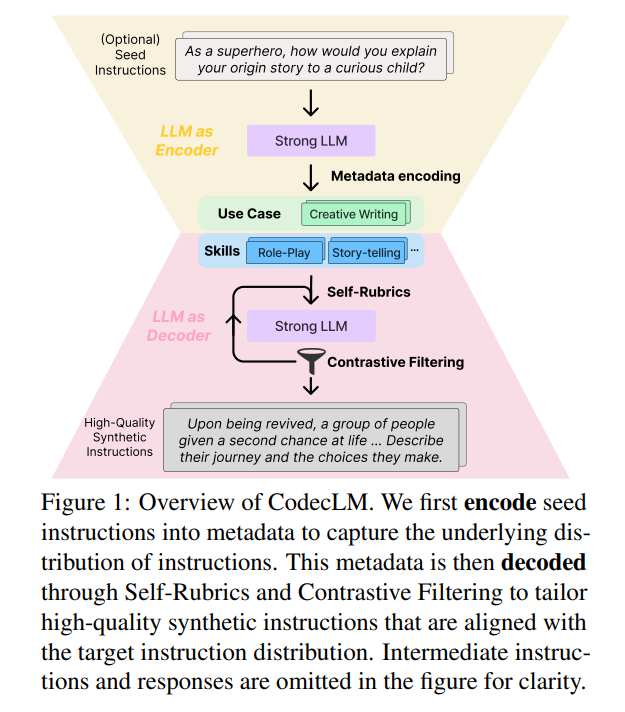
Introducing CodecLM: A Tailored Training Approach
Google Cloud AI presents CodecLM, a groundbreaking framework that tackles LLM misalignment through the generation of customized synthetic data. This innovative approach utilizes an encode-decode mechanism, ensuring optimal LLM performance across diverse tasks.
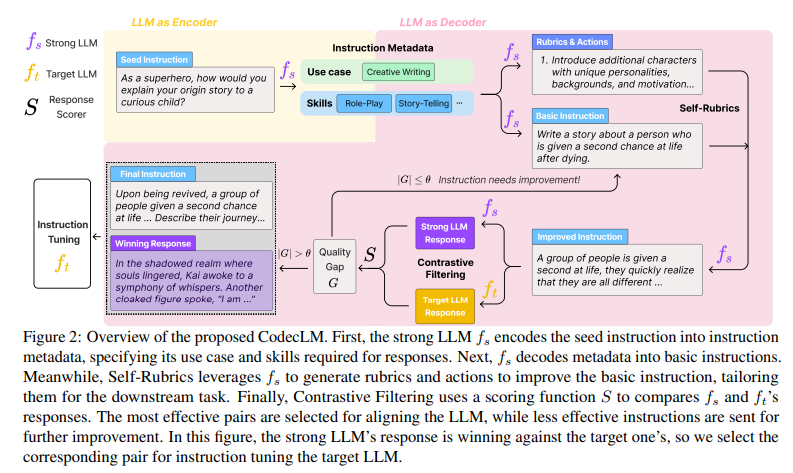
The Power of Encode-Decode with Self-Rubrics and Contrastive Filtering
CodecLM works in two stages:
- Encode: It transforms initial user instructions into concise metadata capturing their essence.
- Decode: This metadata guides the generation of synthetic instructions tailored to specific user needs.
To further elevate the quality and relevance of these synthetic instructions, CodecLM employs two key techniques:
- Self-Rubrics: These dynamically adjust instruction complexity based on the metadata, ensuring they align with user intent.
- Contrastive Filtering: It selects the most effective instruction-response pairs based on performance metrics, optimizing the training data.
Benchmarking Success: CodecLM Outperforms Traditional Methods
Rigorous evaluations across various benchmarks showcase CodecLM’s effectiveness:
- Vicuna Benchmark: Here, CodecLM achieved a 12.5% improvement in Capacity Recovery Ratio (CRR) compared to its closest competitor, reaching 88.75%.
- Self-Instruct Benchmark: A significant 15.2% CRR increase was observed, with CodecLM reaching 82.22%.
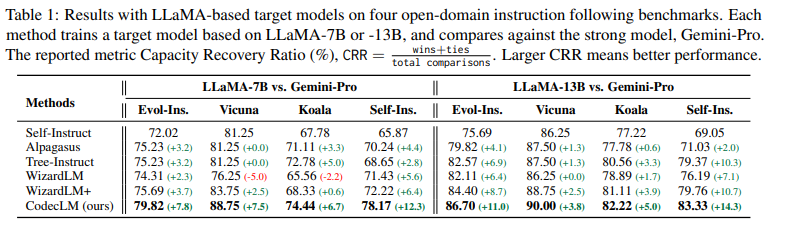
These results demonstrate CodecLM’s ability to significantly enhance LLM accuracy in following complex instructions, ensuring a closer alignment with user-specified tasks.
CodecLM: A Pioneering Step Towards Optimal LLM Performance
By leveraging tailored synthetic data generation, CodecLM represents a significant leap forward in aligning LLMs with user instructions. This innovative framework, powered by an encode-decode approach with Self-Rubrics and Contrastive Filtering, paves the way for more accurate and efficient LLMs, ultimately enabling them to better understand and execute complex user requirements.