Large Language Models (LLMs) have become a game-changer in natural language processing (NLP). Their ability to mimic human-like text, answer intricate questions, and assist with diverse language tasks is truly remarkable. This comprehensive guide delves into the fascinating world of decoder-based LLMs, the architectural marvel driving these advancements.
The Transformer: A Cornerstone Reexamined
Before we delve into the specifics of decoder-based LLMs, let’s revisit the foundational transformer architecture. This groundbreaking approach revolutionized sequence modeling by relying solely on “attention mechanisms.” Unlike traditional models with recurrent or convolutional layers, the transformer excels at capturing complex relationships within data, even those spanning long distances.
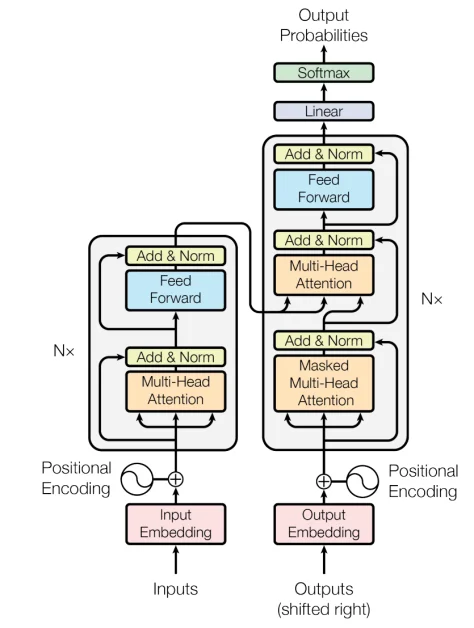
The original transformer comprised two key components: an encoder and a decoder. The encoder meticulously analyzes the input sequence, generating a rich contextual representation. This representation then becomes the decoder’s “fuel” for producing the output sequence. This architecture was initially designed for machine translation, where the encoder processes a source language sentence, and the decoder crafts the corresponding sentence in the target language.
Decoder-Based LLMs: A Shift in Focus
However, decoder-based LLMs take a different approach. They leverage the decoder’s power for various tasks, effectively sidelining the encoder entirely. This shift unlocks a new realm of possibilities in text generation, question answering, and more. In the following sections, we’ll embark on a journey to explore the intricate workings of these captivating models. We’ll delve into the essential building blocks, groundbreaking architectural innovations, and practical implementation details that have positioned decoder-based LLMs at the forefront of NLP research and applications.
Self-Attention: The Secret Sauce of Transformers
The transformer architecture’s magic lies within the self-attention mechanism. This ingenious technique empowers the model to analyze and connect information across the entire input sequence, unlike traditional models that process data one step at a time. Here’s how self-attention works its wonders:
- Projecting the Input: The model takes the input sequence and creates three distinct representations: queries (Q), keys (K), and values (V). Imagine these as search terms, reference points, and the actual information, respectively. These projections are obtained by multiplying the input with carefully chosen weight matrices, essentially fine-tuning the data for the self-attention process.
- Calculating Relevance Scores: For each position in the sequence, the model calculates an attention score. This score reflects how relevant each other position is to the current position being processed. The calculation involves taking the dot product between the corresponding query vector and all key vectors. Essentially, the model is comparing its “search terms” (queries) to all the “reference points” (keys) in the sequence to determine which hold the most valuable information.
- Assembling the Final Output: The attention scores are normalized using a softmax function, ensuring they all sum to one. These scores then act as weights, determining how much influence each value vector (the actual information) has on the final output representation for the current position. In simpler terms, the model takes a weighted average of all the relevant information in the sequence, giving more importance to the most relevant pieces.
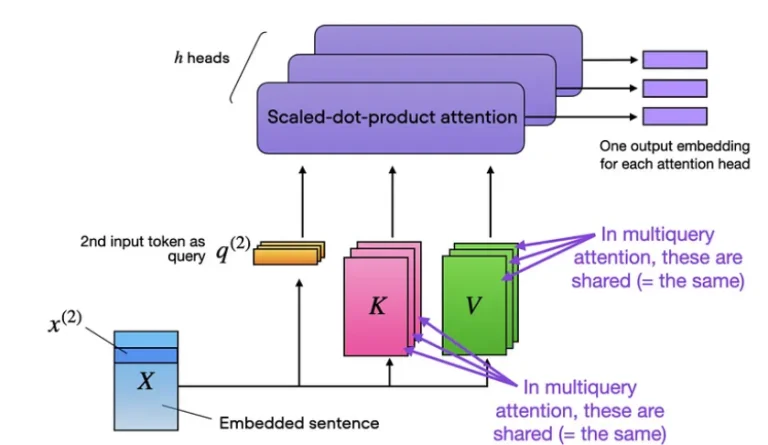
Multi-Head Attention: Expanding the Lens
Self-attention is powerful, but researchers introduced multi-head attention to take it a step further. This variant allows the model to learn different types of relationships within the data by computing attention scores across multiple “heads” simultaneously. Each head has its dedicated set of query, key, and value projections, essentially functioning as independent mini-analyzers focusing on different aspects of the data. This multifaceted approach allows the model to capture a richer and more nuanced understanding of the input sequence.
Architectural Advancements: A Continuous Journey
While the core principles of decoder-based LLMs remain constant, the quest for even better performance, efficiency, and adaptability is ongoing. Researchers are constantly exploring different architectural choices and configurations. In the next section, we’ll delve into these architectural variations and their implications for decoder-based LLMs.
Decoding the Decoder: A Look at Architectural Variations
Decoder-based LLMs come in a variety of flavors, each with its own strengths and attention patterns. Let’s explore the three main architectural types:
- Encoder-Decoder Architecture: The Classic Duo
This architecture resembles the original transformer model, featuring a well-coordinated “encoder” and “decoder” team. The encoder, a master of analysis, processes the input sequence and generates a compressed representation, capturing its essence. This representation then becomes the decoder’s roadmap as it embarks on generating the target sequence. While effective in various NLP tasks, this design is less common among modern LLMs. However, models like Flan-T5 leverage this architecture to achieve impressive results.
- Causal Decoder Architecture: A One-Way Street to Success
The causal decoder architecture takes a more streamlined approach. It utilizes a unidirectional attention mask, ensuring each input token only focuses on the information it has already “seen” and itself. Think of it as reading a sentence from left to right; you can only consider the words you’ve already read, not those ahead. Both input and output tokens reside within the same decoder, fostering a tight-knit processing loop. Pioneering models like GPT-1, GPT-2, and the awe-inspiring GPT-3 are built on this foundation. Notably, GPT-3 showcases exceptional in-context learning capabilities, a testament to the power of the causal decoder architecture. This design has also been widely adopted by other LLMs, including OPT, BLOOM, and Gopher.
- Prefix Decoder Architecture: Bi-directional Insights with a Twist
The prefix decoder architecture, also known as the non-causal decoder, adds a twist to the masking mechanism of causal decoders. It allows for a more nuanced view of the input. Here, the model can attend bidirectionally to the “prefix tokens” (think of it as the initial part of a sentence you’re working on) while maintaining a unidirectional focus on the tokens it has already generated. Similar to the encoder-decoder architecture, prefix decoders can analyze the prefix sequence from both directions and then autoregressively predict the output tokens using the same set of parameters. This approach offers a more comprehensive understanding of the context compared to purely causal decoders. LLMs like GLM130B and U-PaLM utilize this architecture for their impressive text generation abilities.
Decoder-Only Transformers: Autoregressive Powerhouses
The original transformer, while groundbreaking, was designed for tasks like machine translation, which involve a defined input and output sequence. However, many natural language processing tasks are inherently autoregressive. This means the model generates the output one piece at a time, relying on the previously generated elements for context. Think of it like writing a story – you build upon each sentence based on what came before.
This is where the decoder-only transformer shines. It’s a streamlined version of the original architecture, keeping just the decoder component. This streamlined design is perfectly tailored for autoregressive tasks. It generates output tokens one by one, cleverly utilizing the previously generated tokens as its contextual compass.
The key difference between the decoder-only transformer and the original decoder lies in how they handle self-attention. In the decoder-only setting, the self-attention mechanism is carefully modified to prevent the model from peeking ahead at future tokens. This crucial property is known as causality. To achieve this, a technique called “masked self-attention” comes into play. Here, attention scores corresponding to future positions are essentially muted (set to negative infinity) during the normalization step. This effectively masks them out, ensuring the model focuses only on the information it has already processed.
By embracing this autoregressive nature, decoder-only transformers excel in various tasks like:
- Language Modeling: Predicting the next most likely word in a sequence, a fundamental building block for many NLP applications.
- Text Generation: Creating coherent and creative text formats, from poems to scripts, based on a given prompt or starting point.
- Question Answering: Formulating comprehensive answers to user queries by leveraging the context of the question and previously generated text.
The decoder-only transformer’s focus on autoregressive tasks has become a cornerstone of modern NLP advancements, paving the way for groundbreaking applications in text generation and beyond.
Building the Brain of an LLM: Core Components of Decoder-Based Architectures
While self-attention and masked self-attention form the foundation, modern decoder-based LLMs boast a sophisticated architecture with several innovative components. These advancements significantly improve performance, efficiency, and the ability of these models to adapt to diverse tasks. Let’s delve into some of the key elements that power these state-of-the-art language engines:
From Text to Numbers: Input Representation
Before the magic of language processing begins, decoder-based LLMs go through a crucial step: transforming raw text into a numerical format the model can understand. This is achieved through tokenization and embedding techniques.
- Tokenization: Breaking Down the Text – Imagine a chef prepping ingredients. Tokenization acts similarly, breaking down the input text into smaller units called tokens. These tokens can be individual words, subwords (think prefixes or suffixes), or even characters, depending on the chosen strategy. Popular tokenization techniques for LLMs include Byte-Pair Encoding (BPE), SentencePiece, and WordPiece. These methods aim to find a sweet spot between vocabulary size and the level of detail captured in each token. This balance ensures the model can handle even rare or unfamiliar words it might encounter.
- Token Embeddings: Capturing Meaning – Once tokenized, each token is assigned a unique numerical representation known as a token embedding. Think of these embeddings as digital fingerprints, where each token’s semantic and syntactic relationships with other tokens are encoded. These crucial connections are learned by the model during its training process.
- Positional Embeddings: Knowing Your Place – Unlike recurrent models that process text sequentially, transformers handle the entire input sequence at once. This presents a challenge – how does the model know the order of the tokens? Positional embeddings come to the rescue. These embeddings, added to the token embeddings, provide the model with the positional context it needs to distinguish between tokens based on their location in the sequence. Early LLMs relied on fixed positional embeddings based on mathematical functions. However, recent advancements explore learnable positional embeddings or alternative techniques like rotary positional embeddings, further enhancing the model’s understanding of the sequence structure.
Multi-Head Attention Blocks
Multi-head attention blocks are the beating heart of decoder-based LLMs. These intricate layers perform the masked self-attention operation, allowing the model to focus on relevant parts of the input sequence while disregarding future tokens. Imagine a detective meticulously examining a crime scene, but cleverly avoiding peeking at the solution beforehand! These layers are stacked upon each other, with each layer building upon the knowledge gleaned from the previous one. This stacking process enables the model to capture increasingly complex relationships and create progressively richer representations of the input.
Attention Heads: Seeing the World Through Multiple Lenses
Each multi-head attention layer acts like a team of specialists, each with a distinct perspective. These specialists, known as “attention heads,” have their own set of query, key, and value projections. This allows the model to simultaneously attend to different aspects of the input, akin to a detective team investigating a case from various angles. One head might focus on factual information, another on emotional cues, and another on stylistic elements. This multifaceted approach empowers the model to grasp diverse relationships and patterns within the data.
Residual Connections and Layer Normalization: Ensuring Smooth Learning
Training deep neural networks can be a delicate dance. To facilitate this process and mitigate the vanishing gradient problem (where gradients become too small during backpropagation, hindering learning), decoder-based LLMs incorporate two key techniques: residual connections and layer normalization. Residual connections act like shortcuts, adding the input of a layer directly to its output. This ensures that information from earlier layers is preserved and can flow more readily during training. Layer normalization, on the other hand, helps stabilize the activations and gradients within each layer, promoting smoother learning and ultimately enhancing the model’s performance.
Feed-Forward Layers: Adding a Touch of Non-Linearity
Multi-head attention is a powerful tool, but it’s not the only one in the LLM’s arsenal. Feed-forward layers inject another layer of complexity. These layers essentially apply a simple neural network to each position in the sequence. Think of them as adding non-linear twists and turns to the learning process. This allows the model to delve deeper, capturing more intricate representations of the data.
Activation Functions: Choosing the Right Spark
The choice of activation function in the feed-forward layers plays a crucial role in the model’s performance. Just as the right spark plug can optimize an engine, the appropriate activation function can significantly impact LLM effectiveness. Earlier models often relied on the ReLU activation function. However, recent advancements have seen the adoption of more sophisticated options like the Gaussian Error Linear Unit (GELU) or the SwiGLU activation. These newer functions have demonstrated superior performance in the realm of language processing.
Sparse Attention and Efficient Transformers: Tackling Long Sequences
The self-attention mechanism, while powerful, has a computational cost that grows with the length of the sequence. Imagine analyzing every word in a long novel – it can be quite demanding! To address this challenge, researchers have devised several techniques to streamline self-attention, making it more efficient for processing longer sequences. Here are a few key approaches:
- Sparse Attention: Imagine a detective focusing on a few key suspects instead of everyone in the room. Sparse attention techniques operate similarly, selectively attending to a subset of positions in the input sequence rather than exhaustively analyzing every element. This significantly reduces computational complexity while maintaining reasonable performance.
- Sliding Window Attention: This technique, introduced in the Mistral 7B model, tackles long sequences by applying a fixed window size. Each token can only attend to information within its designated window. However, transformer layers have the ability to transmit information across layers. By cleverly leveraging this property, SWA effectively increases the attention span without the quadratic complexity of full self-attention.
- Rolling Buffer Cache: For exceptionally long sequences, memory limitations can arise. The Mistral 7B model combats this issue with a rolling buffer cache. This technique cleverly stores and reuses pre-computed key and value vectors for a specific window size. By avoiding redundant calculations, the model minimizes memory usage and optimizes processing for long sequences.
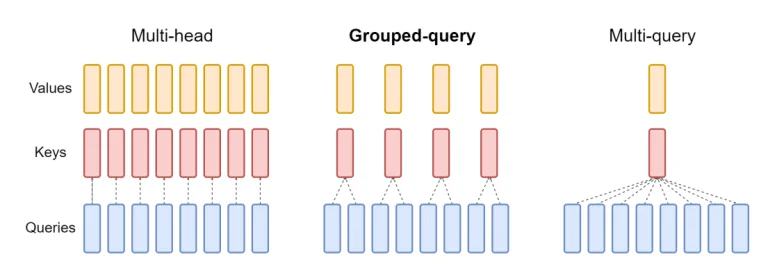
- Grouped Query Attention: This innovative approach, introduced in the LLaMA 2 model, reimagines the multi-head attention mechanism. It divides attention heads into groups, where each group shares a common set of key and value matrices. This approach strikes a balance between the efficiency of multi-query attention and the performance of standard self-attention, enabling faster processing while delivering high-quality results.
These architectural advancements empower decoder-based LLMs to handle longer sequences efficiently, unlocking their potential for tackling even more intricate language processing tasks. As research continues to evolve, we can expect even more groundbreaking techniques to emerge, further pushing the boundaries of what these remarkable models can achieve.
Scaling the Power of Language Models: Size, Techniques, and Creative Applications
Modern LLMs have become titans in the realm of language processing, and their sheer scale is a defining characteristic. These models boast billions, sometimes even hundreds of billions, of parameters, allowing them to capture intricate patterns and relationships within data with remarkable accuracy.
Understanding Model Size: The Building Blocks
The number of parameters in a decoder-based LLM acts as a key performance indicator. This number is primarily influenced by four factors:
- Embedding Dimension (d_model): This determines the size of the vector representation for each token. A larger dimension allows for capturing richer nuances in the data.
- Number of Attention Heads (n_heads): As discussed earlier, attention heads act as specialists within the model, focusing on different aspects of the input. Increasing the number of heads allows for a more comprehensive understanding of the data.
- Number of Layers (n_layers): Similar to stacking building blocks, increasing the number of layers allows the model to build upon its understanding with each layer, capturing progressively more complex relationships.
- Vocabulary Size (vocab_size): This refers to the number of unique words the model can handle. A larger vocabulary enables the model to process a wider range of language.
For instance, the colossal GPT-3 model boasts 175 billion parameters with a configuration of d_model = 12288, n_heads = 96, n_layers = 96, and vocab_size = 50257. This massive scale empowers it to tackle complex language tasks and generate human-quality text.
Taming the Titans: Parallelism and Efficiency Techniques
Training and deploying such behemoths require immense computational resources. To overcome this hurdle, researchers have developed techniques like model parallelism. Here, the model is strategically divided and distributed across multiple GPUs or TPUs (specialized processing units). Each device tackles a specific portion of the computations, enabling efficient training on powerful hardware clusters.
Another innovative approach to scaling LLMs is the mixture-of-experts (MoE) architecture. Imagine a team of experts, each specializing in a particular area. Similarly, MoE combines multiple expert models. Each model focuses on a specific subset of the data or task, collectively achieving superior performance while maintaining computational efficiency. The Mixtral 8x7B model exemplifies this approach, utilizing the Mistral 7B model as its foundation and achieving impressive results.
From Parameters to Creativity: Text Generation and Beyond
One of the most captivating applications of decoder-based LLMs is text generation. These models can craft coherent and natural-sounding text based on a starting point or prompt. Think of it as a creative writing partner – you provide the seed of an idea, and the LLM expands upon it with its vast knowledge and language skills.
Autoregressive Decoding: Building Block by Block
During text generation, LLMs employ a process called autoregressive decoding. Here, the model predicts one word (or token) at a time, drawing upon the previously generated content and the initial prompt. This process continues until a predefined stopping point is reached, such as reaching a maximum length or generating an “end-of-text” signal.
Steering Creativity: Sampling Strategies
To ensure the generated text is both diverse and realistic, various sampling strategies can be employed. These techniques, like top-k sampling or temperature scaling, essentially influence the model’s “creativity level” by adjusting the probability distribution of potential words it can choose from at each step. This allows for a balance between generating unique and unexpected content while maintaining coherence and relevance to the prompt.
Prompt Engineering: The Art of Guiding the Muse
The quality and specificity of the initial prompt significantly impact the generated text. Prompt engineering, the art of crafting effective prompts, has become an essential aspect of utilizing LLMs for various tasks. By carefully crafting the prompt, users can guide the model’s generation process and achieve desired outcomes. Imagine providing a detailed painting prompt to an artist – the more specific you are, the closer the final artwork aligns with your vision.
Human-in-the-Loop Decoding: Refining the Craft
The quest for even more refined and human-quality outputs from LLMs continues. Techniques like reinforcement learning from human feedback (RLHF) are being explored. In this approach, human evaluators provide feedback on the model’s generated text, which is then used to fine-tune the model. This ongoing human-in-the-loop approach helps align the model’s outputs with human preferences and continuously improve its capabilities.
As research and development in LLMs progress, we can expect even more powerful scaling techniques, innovative applications, and a deeper understanding of how to leverage these remarkable tools to unlock the full potential of language and creative expression.
Decoder-Based LLMs: A Look Ahead – Pushing the Boundaries of Language
The world of decoder-based LLMs is a thrilling one, constantly in flux with groundbreaking research and advancements. These models are redefining the boundaries of what language processing can achieve. Let’s delve into some exciting ongoing developments and future possibilities:
Efficiency Redefined: Beyond Sparse Attention
While sparse attention and sliding window attention have been game changers in streamlining LLMs, researchers are on a relentless quest for even more efficient architectures. Alternative transformer variants and novel attention mechanisms are being actively explored. The goal? To further reduce the computational burden without sacrificing (or even enhancing) the model’s performance. Imagine a marathoner – new training techniques aim to optimize these models for peak performance while minimizing energy expenditure.
A World Beyond Text: Multimodal Powerhouses
The future of LLMs is not confined to text alone. Multimodal models are emerging as the next frontier, aiming to seamlessly integrate multiple modalities like images, audio, and video into a unified framework. This opens a treasure trove of possibilities for applications like generating captions that perfectly capture the essence of an image, answering questions based on visual content (think “show, don’t tell” on steroids), and creating rich multimedia experiences.
Taking Control of the Narrative: Fine-Tuning Generation
One of the most sought-after advancements in LLMs is the ability to exert fine-grained control over the generated text. Techniques like controlled text generation and prompt tuning are at the forefront of this endeavor. Imagine wielding a conductor’s baton – these techniques empower users to meticulously guide the style, tone, and specific content of the generated text, ensuring it aligns perfectly with their vision.
Conclusion: A Force for Good, Responsibly
Decoder-based LLMs have become a transformative force in natural language processing, pushing the very limits of language understanding and generation. Their journey began as a streamlined version of the transformer architecture, but they have blossomed into remarkably sophisticated and powerful systems, fueled by cutting-edge techniques and ingenious architectural advancements.
As we continue to explore and refine these models, we can expect even more remarkable breakthroughs in language-related tasks. From crafting compelling narratives to streamlining communication across languages, the potential applications are vast. However, with great power comes great responsibility. Ethical considerations, interpretability challenges, and potential biases inherent in these models demand our attention.
By remaining at the forefront of research, fostering open collaboration, and prioritizing responsible AI development, we can unlock the full potential of decoder-based LLMs. This ensures they are developed and utilized for the benefit of society, in a safe, ethical, and responsible manner. The future of language promises to be remarkable, and decoder-based LLMs are poised to play a pivotal role in shaping it.

