The ability to create expressive and realistic animations from static images and audio has become increasingly sought-after in various fields, including gaming, virtual reality, and digital media. However, generating high-quality animations that seamlessly blend temporal consistency with visual captivation remains a challenge for developers. This complexity arises from the intricate interplay between lip movements, head positioning, and facial expressions – all crucial for a believable and engaging experience.
This article introduces AniPortrait, a novel framework designed to address this challenge. AniPortrait generates high-quality animations driven by two key elements: a reference portrait image and an audio sample.
A Two-Stage Approach to Animation Magic
AniPortrait’s operation unfolds in two distinct stages. In the first stage, the framework extracts intermediate 3D representations from the audio input. These representations are then projected into a sequence of 2D facial landmarks. This process essentially translates the audio’s nuances into precise facial movements.
The second stage leverages a powerful diffusion model, coupled with a motion module. This combination transforms the sequence of facial landmarks into a temporally consistent and photorealistic animation. Imagine breathing life into a portrait, with subtle shifts in expression and movement mirroring the emotions conveyed in the audio.
Exceptional Results and Boundless Potential
Experiments have convincingly demonstrated AniPortrait’s superiority in generating high-quality animations. The framework excels in three key areas:
- Exceptional Visual Quality: The animations boast exceptional detail and realism, making the experience truly immersive.
- Pose Diversity: AniPortrait doesn’t limit itself to static expressions. The framework generates a diverse range of poses, ensuring the animation accurately reflects the audio’s emotional journey.
- Facial Naturalness: The animations maintain a natural flow and fluidity, mimicking the subtle nuances of human facial expressions. These combined elements elevate the perceptual experience, making the animated portrait feel genuinely alive.
Beyond its core functionality, AniPortrait offers remarkable potential in terms of controllability and flexibility. The framework can be effectively applied in various areas, including:
- Facial Reenactment: Imagine animating a historical figure by feeding their portrait and a corresponding speech into AniPortrait. The possibilities for storytelling and education are vast.
- Facial Motion Editing: Fine-tuning specific aspects of an animation, like the intensity of a smile or the tilt of the head, becomes achievable with AniPortrait’s framework.
Breathing Life into Portraits: AniPortrait and the Future of Animation
For years, researchers have pursued the creation of realistic and expressive portrait animations, captivated by their potential applications in gaming, virtual reality, digital media, and beyond. However, achieving this vision remains a challenge. The key lies in balancing temporal consistency – ensuring the animation flows smoothly over time – with visual captivation, where the animation draws the viewer in. The intricate interplay of head position, facial expressions, and lip movements is paramount for achieving this captivating effect.
Traditionally, limited-capacity generators like NeRF, motion-based decoders, and GANs have been used for visual content creation in animation. However, these methods struggle with limited generalization capabilities, often producing unstable and unconvincing results.
A recent breakthrough has been the emergence of diffusion models, capable of generating high-quality images. Building on this advancement, the AniPortrait framework enters the scene.
AniPortrait: A Two-Stage Approach to Animation Magic

AniPortrait tackles the animation challenge with a novel two-stage approach, driven by a reference portrait image and an audio sample.
- Stage One: Capturing Emotion from Audio
The first stage leverages transformer-based models to extract a sequence of 3D facial features – including mesh and head pose – directly from the audio input. These features are then projected into a sequence of 2D facial landmarks. This ingenious process essentially translates the nuances of the audio into precise facial movements, capturing not only lip movements but also subtle expressions and head movements that synchronize with the rhythm of the audio sample.
- Stage Two: Transforming Landmarks into Life
The second stage utilizes a powerful diffusion model, integrated with a custom-designed motion module. This combination transforms the sequence of facial landmarks into a breathtakingly realistic and temporally consistent animation. AniPortrait draws inspiration from the network architecture of the AnimateAnyone model, which utilizes Stable Diffusion 1.5 to generate lifelike and fluid animations based on a reference image and body motion sequences. However, AniPortrait takes this concept a step further. It forgoes the pose guider module from AnimateAnyone, opting for a redesigned solution that maintains a lightweight framework while achieving enhanced precision in generating lip movements.
Exceptional Results and Boundless Potential
Experiments have convincingly demonstrated AniPortrait’s superiority in creating animations. The framework excels in three key areas:
- Unmatched Realism: The animations boast exceptional visual quality and detail, blurring the lines between reality and simulation.
- Pose Diversity: AniPortrait doesn’t limit itself to static expressions. The framework generates a diverse range of poses, ensuring the animation accurately reflects the emotional journey conveyed in the audio.
- Natural Facial Flow: The animations maintain a natural flow and fluidity, mimicking the subtle nuances of human facial expressions. These combined elements elevate the perceptual experience, making the animated portrait feel genuinely alive.
Beyond its core functionality, AniPortrait offers immense potential for future applications, including:
- Facial Reenactment: Imagine animating historical figures by feeding their portrait and a corresponding speech into AniPortrait. The possibilities for storytelling and education are vast.
- Facial Motion Editing: Fine-tuning specific aspects of an animation, like the intensity of a smile or the tilt of the head, becomes achievable with AniPortrait’s framework.
AniPortrait: Unveiling the Magic Behind Breathtaking Animations
AniPortrait, a groundbreaking framework, revolutionizes the creation of high-quality animated portraits. It achieves this by leveraging two key modules – Audio2Lmk and Lmk2Video – working in perfect harmony.
Audio2Lmk: Capturing the Nuance of Speech
Imagine extracting intricate lip movements and facial expressions from a mere audio clip. That’s precisely what the Audio2Lmk module excels at. This sophisticated module employs a pre-trained wav2vec method, renowned for its exceptional generalization capabilities. By meticulously analyzing the audio, it can accurately interpret intonation and pronunciation – crucial ingredients for realistic facial animations.
The extracted information is then processed through a simple yet remarkably effective architecture consisting of two fully-connected layers. This streamlined design not only ensures efficient processing but also maintains exceptional accuracy in transforming audio features into 3D facial meshes.
For pose prediction, AniPortrait relies on the same wav2vec network, but with separate weights compared to the audio-to-mesh module. This distinction acknowledges that pose is more heavily influenced by the audio’s tone and rhythm, differing from the emphasis on precise details required for generating facial meshes.
To account for the context of the entire audio sequence, AniPortrait incorporates a transformer decoder. This powerful tool allows the framework to integrate audio features seamlessly using cross-attention mechanisms. Both modules are trained using the L1 loss function, ensuring optimal results.
Finally, the 3D pose and mesh sequences are transformed into a 2D sequence of facial landmarks using perspective projection. These landmarks serve as crucial input signals for the subsequent stage.
Lmk2Video: Breathing Life into Still Portraits
The Lmk2Video module takes center stage, transforming a reference portrait and a sequence of facial landmarks into a breathtakingly lifelike animation. This module excels in three critical areas:
- Temporal Consistency: The animation flows seamlessly, with each frame smoothly transitioning into the next, creating a captivating viewing experience.
- Motion Alignment: The facial movements perfectly synchronize with the provided landmark sequence, ensuring the animation accurately reflects the emotions conveyed in the audio.
- Visual Cohesion: The generated animation maintains a consistent appearance throughout, staying true to the details of the reference portrait.
The Lmk2Video module draws inspiration from the established AnimateAnyone framework. AniPortrait utilizes the potent Stable Diffusion 1.5 model as its backbone, coupled with a temporal motion module. This combination effectively transforms a sequence of noisy frames into a captivating video.
Furthermore, a dedicated Referencenet network mirrors the structure of Stable Diffusion 1.5. Its role is to extract appearance information from the reference image and integrate it into the backbone network. This meticulous design ensures that the facial identity remains consistent throughout the entire animation.
AniPortrait: Taking Precision to New Heights
AniPortrait surpasses the capabilities of the AnimateAnyone framework by refining the PoseGuider module’s design. The original version featured a limited number of convolution layers where landmark features merged with latent features at the backbone’s input layer.
AniPortrait identified a shortcoming in this approach – the inability to capture intricate lip movements effectively. To address this, the framework incorporates a multi-scale strategy inspired by ConvNet architecture. This allows for the integration of corresponding-scale landmark features into different backbone blocks, resulting in superior precision.
An additional improvement lies in incorporating the reference image’s landmarks as input. The PoseGuider’s cross-attention module facilitates interaction between the target landmarks of each frame and the reference landmarks. This empowers the network to understand the relationship between appearance and facial landmarks, leading to the generation of animations with unparalleled precision and realism.
AniPortrait: Bringing Portraits to Life – Implementation and Astounding Results
AniPortrait’s innovative framework translates into a two-stage implementation process, meticulously designed to achieve exceptional results.
Stage One: Capturing the Essence of Speech
The first stage, Audio2Lmk, relies on the powerful wav2vec2.0 component as its backbone. This component boasts exceptional generalization capabilities, ensuring accurate interpretation of diverse speech patterns. To extract the necessary information, AniPortrait leverages the MediaPipe architecture. This architecture facilitates the extraction of both 3D facial meshes and 6D poses for annotations – crucial elements for generating realistic facial animations.
The training data for the Audio2Mesh component originates from a meticulously curated internal dataset. This dataset features nearly 60 minutes of high-quality speech data, all sourced from a single speaker. To guarantee the stability of the extracted 3D meshes, the voice actor maintains a steady head position while facing the camera during recording.
Stage Two: Breathing Life into the Portrait
The Lmk2Video module takes center stage in the second phase. Here, AniPortrait employs a two-stage training approach to achieve optimal performance.
- Phase One: Refining the Network
The first training phase focuses on meticulously refining ReferenceNet and PoseGuider, the 2D component of the backbone network. During this stage, the motion module is intentionally left out.
- Phase Two: Honing Motion
In the second training step, all other components are frozen. Here, the focus shifts entirely to training the motion module. To achieve this, AniPortrait utilizes two large-scale, high-quality facial video datasets. The MediaPipe component is employed to process all the data, extracting precise 2D facial landmarks.
To further enhance the network’s sensitivity towards intricate lip movements, AniPortrait employs a clever technique. When rendering the pose image from 2D landmarks, the upper and lower lips are distinguished using distinct colors. This subtle yet effective approach empowers the network to capture even the most nuanced lip motions.
The Power of AniPortrait: Exceptional Results and Boundless Potential
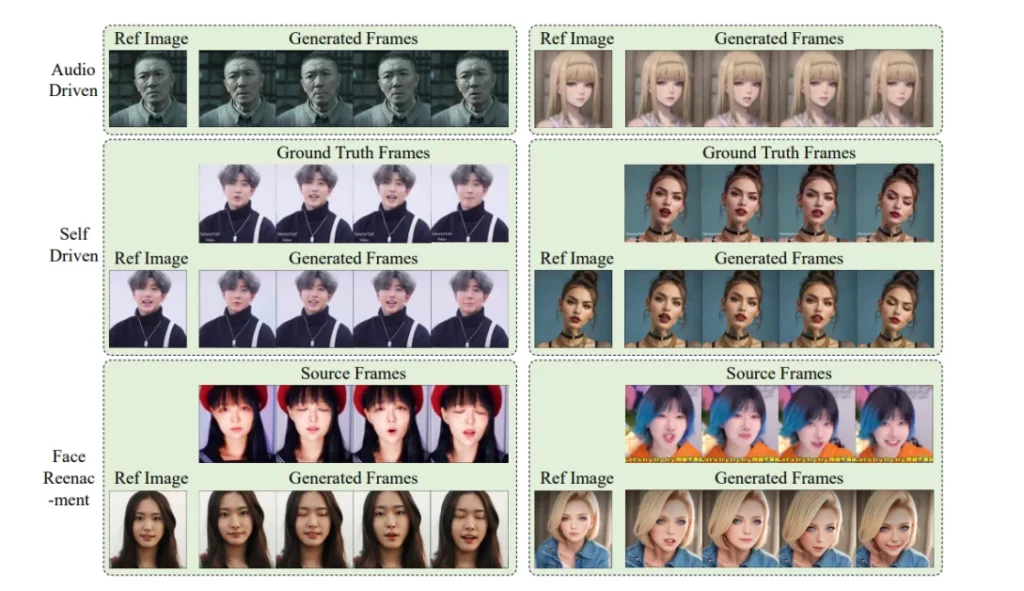
The results speak for themselves. As illustrated, AniPortrait generates animations that boast superior quality and unparalleled realism. This is achieved by leveraging an intermediate 3D representation. This representation offers a unique advantage – the ability to manipulate the output based on specific requirements. Imagine extracting landmarks from a source and altering its identity. With AniPortrait, this translates to generating a facial reenactment effect, opening doors to exciting applications.
Conclusion: A Framework Poised to Revolutionize
AniPortrait stands as a testament to the power of innovative frameworks. By simply inputting a reference image and an audio sample, users can generate portrait videos brimming with natural head movements and smooth lip motion. The framework leverages the robust capabilities of diffusion models, resulting in animations that showcase exceptional visual quality and lifelike movement.
Beyond its core functionality, AniPortrait holds immense potential for the future. Its controllability and flexibility pave the way for exciting applications in facial reenactment, facial motion editing, and beyond. AniPortrait is not just a framework; it’s a gateway to a future filled with expressive and captivating animated portraits.

