The intricate world of graphs, where entities dance as nodes and their connections form a vibrant network, holds immense potential for unlocking breakthroughs in diverse fields. Social networks, knowledge bases, biological systems – these are just a few domains where graph structures illuminate complex relationships. Effectively navigating these interconnected landscapes is essential for advancements in network science, drug discovery, and recommender systems.
Graph Neural Networks (GNNs): Unveiling the Power of Relationships
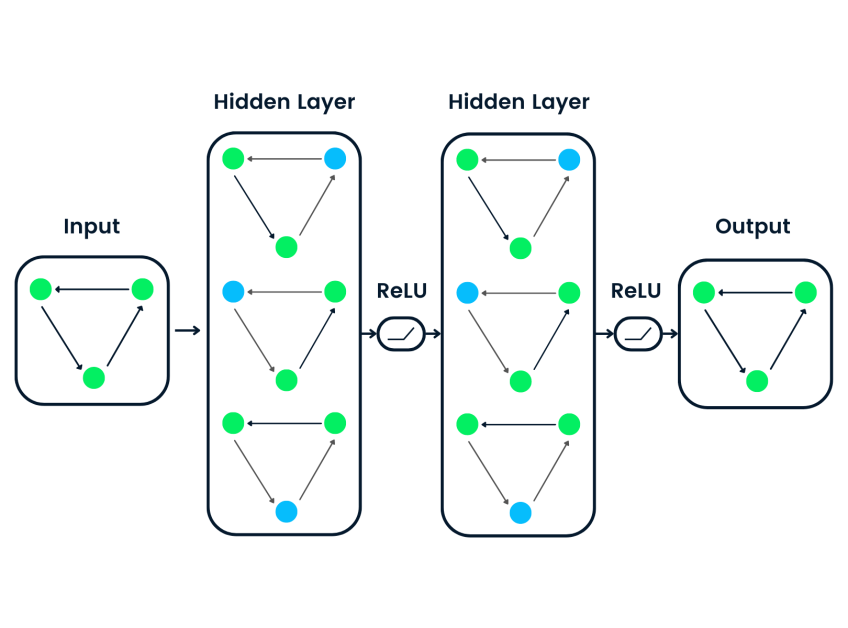
Enter Graph Neural Networks (GNNs), a powerful deep learning framework that has revolutionized graph machine learning. By factoring the graph’s topology into its architecture, GNNs can learn hidden patterns within these relational structures. Imagine a neural network that not only understands individual nodes (entities) but also grasps the significance of their connections. This empowers GNNs to excel at tasks like node classification, link prediction, and graph classification across various applications.
Challenges and the Rise of the Language Giants
While GNNs have ushered in a new era, hurdles remain. Acquiring high-quality labeled data for training GNNs can be a costly and time-consuming endeavor. Additionally, GNNs can struggle when faced with diverse graph structures or when encountering data that significantly deviates from what they were trained on (out-of-distribution generalization).
Meanwhile, Large Language Models (LLMs) like GPT-4 and LaMDA have taken the world by storm with their phenomenal natural language processing capabilities. These AI marvels, trained on massive datasets with billions of parameters, exhibit remarkable few-shot learning (learning from minimal data), task-agnostic generalization (adapting to new tasks), and even commonsense reasoning – skills once considered elusive for AI systems.
A Symbiotic Future: Language Meets Graph Intelligence
The success of LLMs has ignited a wave of research exploring their potential for enhancing graph machine learning. Imagine the possibilities: leveraging the knowledge and reasoning prowess of LLMs to empower traditional GNN models. Conversely, the structured representations and factual knowledge inherent in graphs could be instrumental in addressing some key limitations of LLMs, such as their tendency to generate hallucinations (fabricated information) and their lack of interpretability (difficulty in understanding how they arrive at their outputs).
This article embarks on a captivating journey into the heart of this burgeoning field, where graph machine learning and large language models converge. We will delve into the exciting ways LLMs can be harnessed to elevate various aspects of graph ML, explore how graph knowledge can be incorporated into LLMs, and discuss the emerging applications and promising future directions that lie ahead at this fascinating intersection.
Hidden Patterns: Graph Neural Networks and the Power of Self-Supervised Learning
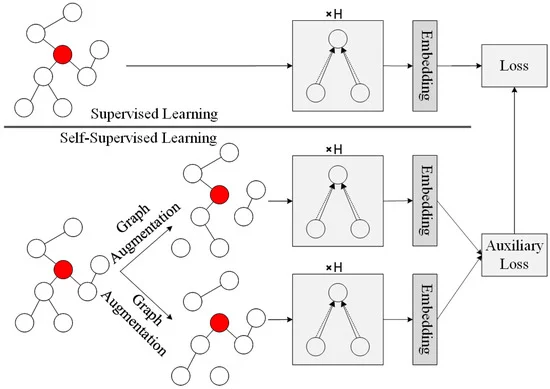
The realm of graph data, where entities intertwine in a complex dance of relationships, presents unique challenges and opportunities for machine learning. To unlock its potential, we must delve into two powerful techniques: Graph Neural Networks (GNNs) and Self-Supervised Learning.
GNNs: Decoding the Language of Relationships
Unlike traditional neural networks, GNNs possess the remarkable ability to process information directly on graph-structured data. Imagine a network that not only understands individual data points (nodes) but also grasps the significance of the connections between them. GNNs achieve this feat through a process called “neighborhood aggregation,” where each node incorporates information from its neighboring nodes to refine its own representation.
Over the years, a diverse array of GNN architectures have emerged, each employing unique methods for processing information within the network. Some prominent examples include Graph Convolutional Networks (GCNs), GraphSAGE, Graph Attention Networks (GATs), and Graph Isomorphism Networks (GINs).
Recently, a new wave of innovation has arrived in the form of graph transformers. These models borrow the powerful “self-attention” mechanism from natural language processing, enabling them to capture long-range dependencies across the entire graph – a capability exceeding that of purely neighborhood-based GNNs. GraphormerTransformer and GraphFormers are just a few examples at the forefront of this exciting development.
Self-Supervised Learning: Extracting Knowledge from the Unknown
While GNNs are adept at learning representations from graph data, their true power can be restricted by the limited availability of large, labeled datasets required for supervised training. Self-supervised learning steps in as a game-changer, offering a paradigm shift in how we train GNNs. It allows these models to leverage unlabeled graph data by constructing “pretext tasks” – essentially, fabricated challenges designed to teach the GNN valuable lessons without the need for explicit labels.
Here’s a glimpse into some popular pretext tasks employed for self-supervised GNN pre-training:
- Node Property Prediction: Imagine randomly masking or corrupting some of a node’s features. The GNN then attempts to reconstruct the missing information, sharpening its understanding of node properties within the graph structure.
- Edge/Link Prediction: Can the GNN predict if a connection exists between two specific nodes, based solely on the overall graph structure? This task hones the model’s ability to identify potential relationships within the network.
- Contrastive Learning: The GNN is presented with multiple “views” of the same graph, some with slight variations. By maximizing similarities between these views and pushing apart views from different graphs entirely, the model learns to differentiate meaningful patterns from random noise.
- Mutual Information Maximization: This approach focuses on maximizing the correlation between local node representations and a broader target representation, such as the overall graph embedding. By strengthening these connections, the GNN refines its understanding of how individual nodes contribute to the larger structure.
These pretext tasks empower the GNN to extract valuable structural and semantic information from unlabeled graph data during pre-training. Following this pre-training phase, the GNN can be “fine-tuned” on a smaller set of labeled data, allowing it to excel at downstream tasks like node classification, link prediction, and graph classification.
The benefits of self-supervision are undeniable. GNNs pre-trained using this approach exhibit superior generalization abilities, increased robustness to variations in data distribution, and improved efficiency compared to models trained from scratch. However, there’s still room for advancement. In the next section, we’ll explore how Large Language Models (LLMs) can be harnessed to address these limitations and unlock the full potential of GNNs.
Language Meets Graph Intelligence: How Large Language Models are Revolutionizing Graph Machine Learning
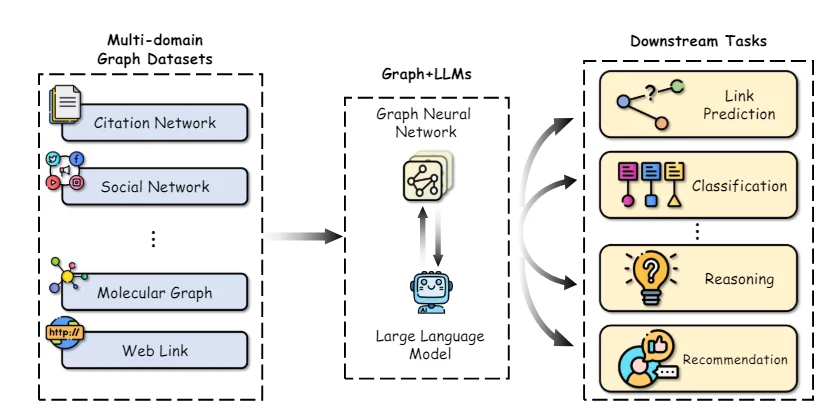
The phenomenal natural language processing prowess of Large Language Models (LLMs) has ignited a wave of innovation in graph machine learning. These AI marvels, capable of understanding complex language, reasoning, and learning from minimal data, are poised to revolutionize the way we approach graph-based tasks. Let’s delve into some key research directions at this exciting intersection:
Unlocking the Power of Textual Data
A significant challenge in GNNs lies in extracting meaningful representations from nodes and edges, especially when they contain rich textual information like descriptions, titles, or abstracts. Traditional methods often fall short, failing to capture the nuances of language. Here’s where LLMs shine. Recent research demonstrates the power of leveraging LLMs as sophisticated text encoders. Studies by Chen et al. showcase how encoding textual node attributes with GPT-3 leads to significant performance improvements in node classification tasks compared to traditional word embeddings.
LLMs go beyond simple encoding. They can be harnessed to generate augmented information from existing text attributes, fostering a semi-supervised learning approach. TAPE, for instance, utilizes LLMs to generate potential labels or explanations for nodes, effectively creating additional training data. KEA employs LLMs to extract key terms from text attributes and obtain detailed descriptions, further enriching feature representations. By infusing their superior natural language understanding into GNNs, LLMs empower these models to leverage textual data with unprecedented effectiveness.
Breaking Free from the Data Bottleneck
One of the LLMs’ greatest strengths is their ability to perform remarkably well on new tasks with minimal labeled data, thanks to their vast pre-training on text corpora. This “few-shot learning” capability can be a game-changer for GNNs, which often require large amounts of labeled data for optimal performance.
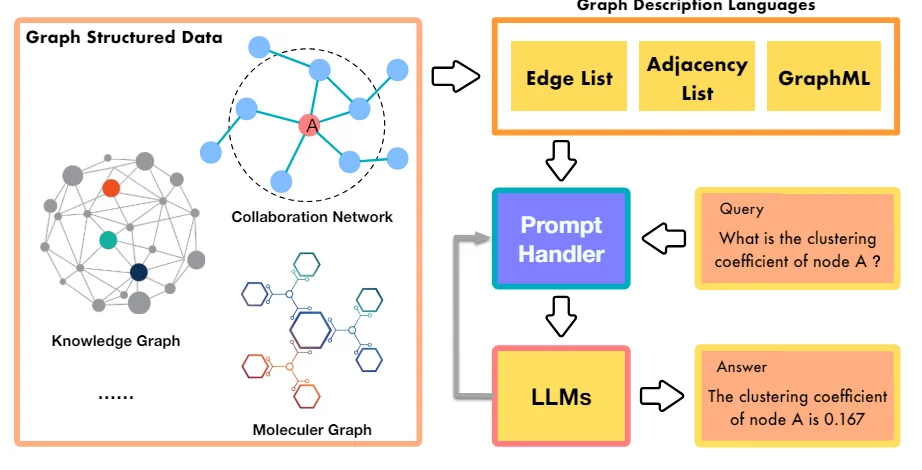
One approach involves using LLMs to directly predict graph properties by describing the graph structure and node information in natural language prompts. Methods like InstructGLM and GPT4Graph fine-tune LLMs like LLaMA and GPT-4 using strategically designed prompts that incorporate details like node connections and neighborhoods. These tuned LLMs can then generate predictions for tasks like node classification and link prediction, even in zero-shot scenarios (without any labeled data during inference).
A Symbiotic Relationship: LLMs and GNNs Working Together
While using LLMs as standalone predictors holds promise, their performance can suffer for complex graph tasks where explicit structural modeling is crucial. This has led to the exploration of hybrid approaches that combine the strengths of both LLMs and GNNs. In these models, GNNs handle the task of encoding the graph structure, while LLMs provide a deeper semantic understanding of nodes based on their textual descriptions.
GraphLLM exemplifies this concept, exploring two strategies: 1) LLMs as Enhancers, where LLMs encode text node attributes before feeding them to the GNN, and 2) LLMs as Predictors, where the LLM takes the intermediate representations from the GNN as input to make final predictions. GLEM takes this a step further by proposing a learning algorithm that allows the LLM and GNN components to iteratively improve each other’s performance.
By leveraging the few-shot learning capabilities of LLMs and enabling semi-supervised augmentation techniques, LLM-enhanced graph learning methods pave the way for exciting new applications and a significant boost in data efficiency. This synergistic approach holds the potential to unlock the full potential of graph machine learning, leading to breakthroughs in diverse fields ranging from social network analysis to drug discovery.
The Symbiosis of Language and Structure: How Graphs Can Empower Large Language Models
Large Language Models (LLMs) have taken the world by storm, demonstrating remarkable abilities in natural language processing, reasoning, and even learning from minimal data. However, these marvels still grapple with limitations such as generating factually incorrect information (hallucinations), lacking transparency in their reasoning process, and struggling to maintain consistent factual knowledge.
Enter graphs, particularly knowledge graphs – structured repositories of factual information from reliable sources. These structures offer a promising avenue to address the shortcomings of LLMs. Here’s how researchers are forging a powerful union between these two domains:
Knowledge Graphs: Instilling Factual Grounding
Similar to the way LLMs are pre-trained on massive text corpora, recent research explores pre-training them on knowledge graphs. This aims to imbue LLMs with a stronger grasp of facts and enhance their reasoning capabilities. Some approaches modify the input data by simply combining factual triples from knowledge graphs with natural language text during pre-training. For instance, E-BERT aligns entity vectors from knowledge graphs with word embeddings used by BERT, while K-BERT constructs structures that encompass the original sentence alongside relevant knowledge graph triples.
LLMs: Supercharging Graph Machine Learning
Researchers have devised several ways to integrate LLMs into the graph learning pipeline, each offering unique advantages and applications. Let’s delve into some prominent roles LLMs can play:
- LLMs as Enhancers: Imagine an LLM acting as a knowledge refinery for graph data. By leveraging its ability to generate explanations, identify relevant knowledge entities, or create pseudo-labels, LLMs can enrich the semantic information available to a Graph Neural Network (GNN). This enriched data leads to improved node representations and superior performance on downstream tasks.
A prime example is the TAPE model. This approach utilizes ChatGPT to generate explanations and pseudo-labels for papers within a citation network. These are then used to fine-tune a language model, and the resulting embeddings are fed into a GNN for node classification and link prediction tasks, achieving state-of-the-art results.
- LLMs as Predictors: Instead of solely enhancing input features, some approaches empower LLMs to act as the primary predictor for graph-related tasks. This involves converting the graph structure into a textual representation that the LLM can understand. The LLM then generates the desired output, such as node labels or predictions about the entire graph.
One notable example is the GPT4Graph model. This approach utilizes the Graph Modelling Language (GML) to represent graphs and leverages the powerful GPT-4 LLM for zero-shot graph reasoning tasks (performing well without any labeled data during training).
- GNN-LLM Alignment: Another line of research focuses on aligning the embedding spaces of GNNs and LLMs. This allows for a seamless integration of structural and semantic information. Essentially, these approaches treat the GNN and LLM as separate modalities and employ techniques like contrastive learning or distillation to create a unified representation space.
For instance, the MoleculeSTM model uses a contrastive objective to align the embeddings of a GNN and an LLM. This enables the LLM to incorporate structural information from the GNN, while the GNN benefits from the LLM’s semantic knowledge.
Bridging the Gap: Challenges and Solutions
While the integration of LLMs and graph learning holds immense promise, several hurdles need to be addressed:
- Efficiency and Scalability: LLMs are known for being resource-intensive, often requiring vast computational power and billions of parameters for training and inference. This can be a significant bottleneck for deploying LLM-enhanced graph learning models in real-world scenarios, especially on devices with limited resources.
One potential solution is knowledge distillation. Here, the knowledge from a large LLM (teacher model) is transferred to a smaller, more efficient GNN (student model).
- Data Leakage and Evaluation: The vast amounts of publicly available data used to pre-train LLMs may include test sets from common benchmark datasets. This can lead to data leakage and inflated performance metrics. Researchers are starting to collect new datasets or sample test data from time periods after the LLM’s training cut-off to mitigate this issue.
Additionally, establishing fair and comprehensive evaluation benchmarks for LLM-enhanced graph learning models is crucial to assess their true capabilities and enable meaningful comparisons.
- Transferability and Explainability: While LLMs excel at zero-shot and few-shot learning, their ability to transfer knowledge across diverse graph domains and structures remains an open challenge. Improving the transferability of these models is a critical research area.
Furthermore, enhancing the explainability of LLM-based graph learning models is essential for building trust and enabling their adoption in high-stakes applications. Leveraging the inherent reasoning capabilities of LLMs through techniques like chain-of-thought prompting can contribute to improved explainability.
The Power of Language Meets Structure: Real-World Applications of LLM-Enhanced Graph Learning
The marriage of Large Language Models (LLMs) and graph machine learning is rapidly transforming the landscape of AI. This powerful union unlocks exciting possibilities, particularly for tasks involving graphs rich in textual information. Here, we explore how this synergy is making waves across various real-world applications:
1. Unveiling the Secrets of Molecules: Drug Discovery with Enhanced Precision
In the realm of computational chemistry and drug discovery, LLMs are proving to be invaluable allies. By incorporating structural information from molecular graphs, LLMs are enhancing the prediction of molecular properties. The LLM4Mol model exemplifies this approach. It harnesses the power of ChatGPT to generate explanations for SMILES string representations of molecules. These explanations are then used to significantly improve the accuracy of property prediction tasks, paving the way for faster and more targeted drug discovery.
2. Building a Web of Knowledge: Enhancing Knowledge Graph Completion and Reasoning
Knowledge graphs, a specialized type of graph structure, represent real-world entities and their intricate relationships. LLMs are emerging as powerful tools for tasks like knowledge graph completion and reasoning. In these tasks, the model must simultaneously consider both the structure of the graph and the textual information associated with entities (e.g., their descriptions). By leveraging LLMs, we can build more comprehensive and robust knowledge graphs, leading to advancements in various fields that rely on structured information.
3. Recommending What Matters: Revolutionizing Recommender Systems
Recommender systems, a cornerstone of e-commerce and entertainment platforms, often rely on graph structures to represent user-item interactions. Nodes represent users and items, while edges denote interactions or similarities. LLMs can significantly enhance these graphs by generating additional user and item information or reinforcing existing interaction edges. Imagine an LLM that, based on your past reading habits, not only recommends new books but also generates detailed summaries or identifies underlying connections between seemingly disparate works. This personalized approach has the potential to revolutionize the way we interact with recommender systems.
Conclusion: A Gateway to the Future
The synergy between LLMs and graph machine learning represents a captivating new frontier in AI research. By harnessing the strengths of both – the structural reasoning power of GNNs and the exceptional semantic understanding of LLMs – we can unlock a new era of graph learning, particularly for text-rich graphs.
However, significant challenges remain in areas like efficiency, scalability, transferability, and explainability. Researchers are actively exploring solutions like knowledge distillation, fair evaluation benchmarks, and multimodal integration to pave the way for the practical deployment of LLM-enhanced graph learning models in real-world applications. As these challenges are addressed, we can expect this powerful union to unlock a multitude of groundbreaking advancements across diverse fields.

